")
")
W erze zaawansowanej sztucznej inteligencji, rozwój modeli językowych odgrywa kluczową rolę w automatyzacji zadań związanych z przetwarzaniem języka naturalnego. Jednym z czołowych projektów open source, który integruje najnowsze technologie w tej dziedzinie, jest Ollama. Projekt ten wykorzystuje innowacyjne modele językowe, takie jak LLaMA3, Gemini oraz Mistral, aby dostarczać narzędzi o wysokiej skuteczności i wszechstronności.
LLaMA3: Przodujący w zrozumieniu języka
LLaMA3 (Large Language Model Autoregressive Algorithm) to zaawansowany model językowy, który wyróżnia się zdolnością do generowania wysokiej jakości tekstu, rozumienia kontekstu i przewidywania dalszych fragmentów tekstu. Dzięki zaawansowanym algorytmom, LLaMA3 znajduje zastosowanie w wielu dziedzinach, od automatyzacji obsługi klienta po analizę sentimentów.
Gemini: Synteza kreatywności i precyzji
Model Gemini jest zaprojektowany tak, aby łączyć kreatywność z precyzją w generowaniu tekstu. Jego unikalna architektura pozwala na tworzenie treści, które są nie tylko spójne, ale także innowacyjne. Dzięki temu Gemini jest idealnym narzędziem do zastosowań takich jak pisanie kreatywne, tworzenie scenariuszy czy generowanie treści marketingowych.
Mistral: Szybkość i efektywność
Mistral to model językowy skoncentrowany na wydajności i szybkości działania. Został zoptymalizowany pod kątem przetwarzania dużych ilości danych w krótkim czasie, co czyni go niezastąpionym w zastosowaniach, gdzie liczy się szybka reakcja i przetwarzanie w czasie rzeczywistym. Mistral znajduje zastosowanie w analizie danych, filtrowaniu informacji oraz w aplikacjach wymagających natychmiastowej odpowiedzi.
Projekt Ollama integruje te nowoczesne modele językowe, tworząc wszechstronne i potężne narzędzie do przetwarzania języka naturalnego. Dzięki otwartości kodu, społeczność może nie tylko korzystać z tych zaawansowanych technologii, ale także przyczyniać się do ich rozwoju i udoskonalania.
Więcej informacji na temat projektu Ollama oraz dostęp do kodu źródłowego można znaleźć na ich stronie GitHub oraz blogu.
Ollama na laptopie z Linux
Stosować można Ollama lokalnie przy użyciu karty graficznej. Model jest ładowany w pamięć karty a procesory karty używane są do interpretacji. Wtedy szybkość odpowiedzi modelu jest porównywalna z rozwiązaniami dostępnymi online. Proste rysunki i diagramy też nie stanowią problemu. Prędkość odpowiedzi przy użyciu CPU nie jest imponująca. W internecie jest dostępny plik dla docker-compose dla tych, którzy nie chcą instalować aplikacji lokalnie: https://github.com/valiantlynx/ollama-docker/blob/main/docker-compose-ollama-gpu.yaml
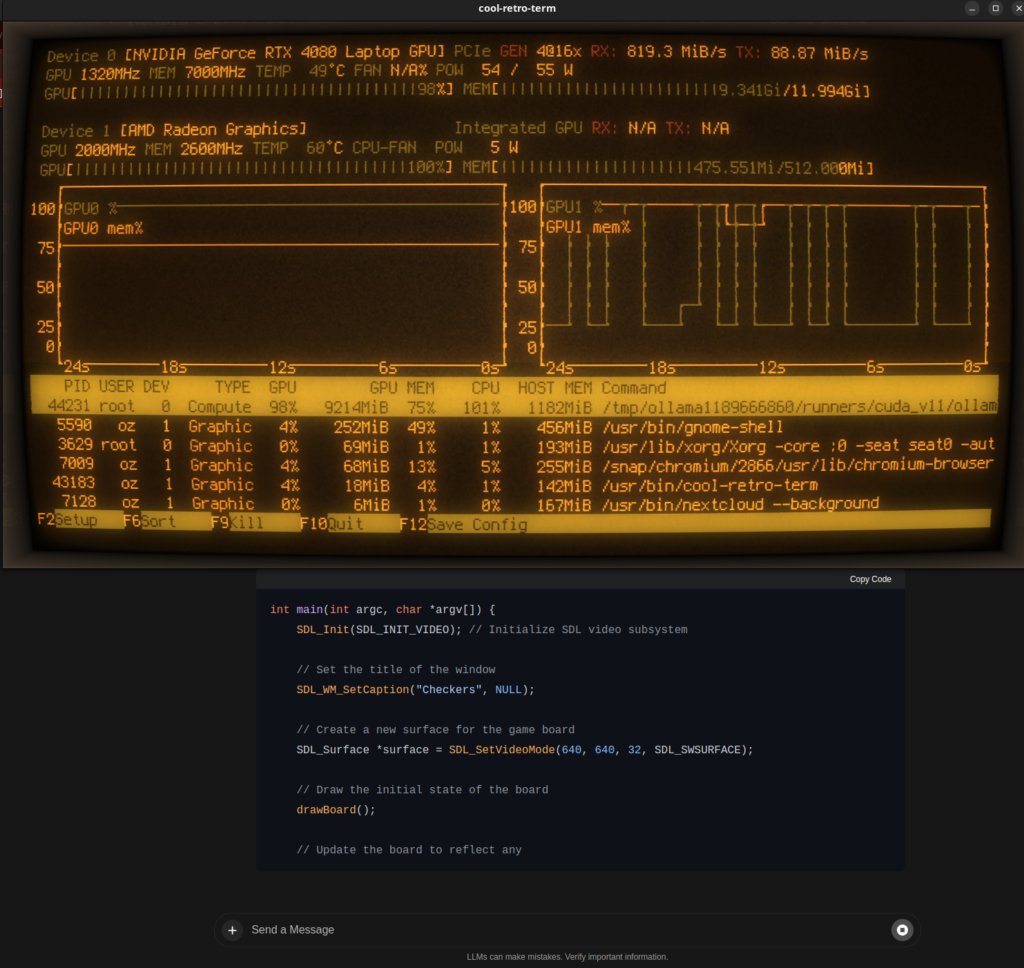
Wybór dostępnych modeli
Ollama wspiera wiele różnych modeli językowych, a także modele użytkowników, które można tworzyć na podstawie modeli bazowych. Każdy model bazowy dostępny jest w różnych jakościach, czyli zastosowanych parametrów i danych przy nauczaniu. Lista wszystkich modeli bazowych znajduje się tu: https://ollama.com/library
Istotne dla wyboru właściwego modelu są:
– pojemność pamięci karty graficznej. Jeśli model się nie zmieści w jej pamieć ollama server użyje automatycznie pamięci głównej i głównego procesora, zamiast karty graficznej. Podane wielkości modeli w bibliotece są mniejsze, niż potrzebna przestrzeń pamięci karty graficznej.
– zadanie modelu. Są modele wyspecjalizowane w pisaniu programów, tłumaczeniu tekstów, czy analizie naukowej. Są też modele, które próbują obsłużyć wszystkie te pola. Jednak jakościowo i ze względu na niską pojemność kart graficznych, warto wybrać wyspecjalizowany model.

